Publications
publications by categories in reversed chronological order. generated by jekyll-scholar.
2025
- Decomposed Learning: An Avenue for Mitigating GrokkingGabryel Mason-Williams and Israel Mason-Williams2025
Grokking is a delayed transition from memorisation to generalisation in neural networks. It challenges perspectives on efficient learning, particularly in structured tasks and small-data regimes. We explore grokking in modular arithmetic from the perspective of a training pathology. We use Singular Value Decomposition (SVD) to modify the weight matrices of neural networks by changing the representation of the weight matrix, W, into the product of three matrices, U,Σand V^T. Through empirical evaluations on the modular addition task, we show that this representation significantly reduces the effect of grokking and, in some cases, eliminates it.
@article{masonwilliams2025decomposedlearning, title = {Decomposed Learning: An Avenue for Mitigating Grokking}, author = {Mason-Williams, Gabryel and Mason-Williams, Israel}, publisher = {ICML 2025 Workshop on Methods and Opportunities at Small Scale (MOSS)}, year = {2025} } - Data Free Metrics Are Not Reparameterisation Invariant Under the Critical and Robust Layer PhenomenaGabryel Mason-Williams, Israel Mason-Williams, and Fredrik Dahlqvist2025
Data-free methods for analysing and understanding the layers of neural networks have offered many metrics for quantifying notions of strong" versus weak" layers, with the promise of increased interpretability. We examine how robust data-free metrics are under random control conditions of critical and robust layers. Contrary to the literature, we find counter-examples that provide counter-evidence to the efficacy of data-free methods. We show that data-free metrics are not reparameterisation invariant in these conditions and lose predictive capacity across correlation measures, RMSE, Person Coefficient and Kendall’s Tau measure. Thus, we argue that to understand neural networks fundamentally, we must rigorously analyse the interactions between data, weights, and resulting functions that contribute to their outputs – contrary to traditional Random Matrix Theory perspectives.
@article{masonwilliams2025datafreemetricsarenotreparameterisationinvariantunderthecriticalandrobustlayerphenomena, title = {Data Free Metrics Are Not Reparameterisation Invariant Under the Critical and Robust Layer Phenomena}, author = {Mason-Williams, Gabryel and Mason-Williams, Israel and Dahlqvist, Fredrik}, publisher = {ICML 2025 Workshop on High-dimensional Learning Dynamics (HiLD)}, year = {2025} } - Reproducibility: The New Frontier in AI GovernanceIsrael Mason-Williams and Gabryel Mason-Williams2025
AI Policymakers are responsible for delivering effective governance mechanisms that can provide safe, aligned and trustworthy AI development. However, the information environment offered to policymakers is characterized by an unnecessarily low signal-to-noise ratio, favouring regulatory capture and creating deep uncertainty and divides on which risks should be prioritized from a governance perspective. We posit that the current speed of publication in AI combined with the lack of strong scientific standards, via weak reproducibility protocols, effectively erodes the power of policymakers to enact meaningful policy and governance protocols. Our paper outlines how AI research could adopt stricter reproducibility guidelines to assist governance endeavours and improve consensus on the risk landscapes posed by AI. We evaluate the forthcoming reproducibility crisis within AI research through the lens of reproducibility crises in other scientific domains and provide a commentary on how adopting preregistration, increased statistical power and negative result publication reproducibility protocols can enable effective AI governance. While we maintain that AI governance must be reactive due to AI’s significant societal implications we argue that policymakers and governments must consider reproducibility protocols as a core tool in the governance arsenal and demand higher standards for AI research.
@article{masonwilliams2025reproducibilitythenewfrontierinaigovernance, title = {Reproducibility: The New Frontier in AI Governance}, author = {Mason-Williams, Israel and Mason-Williams, Gabryel}, publisher = {ICML 2025 Workshop on Technical AI Governance (TAIG)}, year = {2025} }
2024
-
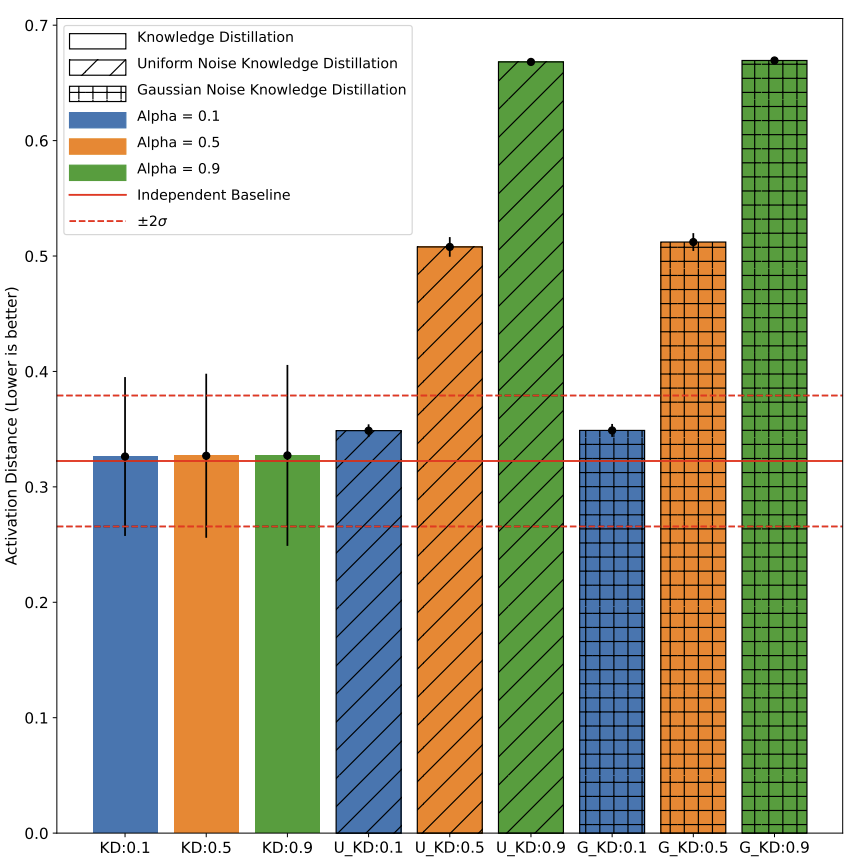 Knowledge Distillation: The Functional PerspectiveIsrael Mason-Williams, Gabryel Mason-Williams, and Mark Sandler2024
Knowledge Distillation: The Functional PerspectiveIsrael Mason-Williams, Gabryel Mason-Williams, and Mark Sandler2024Empirical findings of accuracy correlations between students and teachers in the knowledge distillation framework have served as supporting evidence for knowl- edge transfer. In this paper, we sought to explain and understand the knowledge transfer derived from knowledge distillation via functional similarity, hypothesising that knowledge distillation provides a functionally similar student to its teacher model. While we accept this hypothesis for two out of three architectures across a range of metrics for functional analysis against four controls, the results show that knowledge transfer is significant but it is less pronounced than expected for conditions that maximise opportunities for functional similarity. Furthermore, results from the use of Uniform and Gaussian Noise as teachers suggest that the knowledge-sharing aspects of knowledge distillation inadequately describe the accuracy benefits witnessed when using the knowledge distillation training setup itself. Moreover, in the first instance, we show that knowledge distillation is not a compression mechanism but primarily a data-dependent training regulariser with a small capacity to transfer knowledge in the best case.
@article{mason2024knowledge, title = {Knowledge Distillation: The Functional Perspective}, author = {Mason-Williams, Israel and Mason-Williams, Gabryel and Sandler, Mark}, publisher = {NeurIPS 2024 Workshop on Scientific Methods for Understanding Deep Learning}, year = {2024} } -
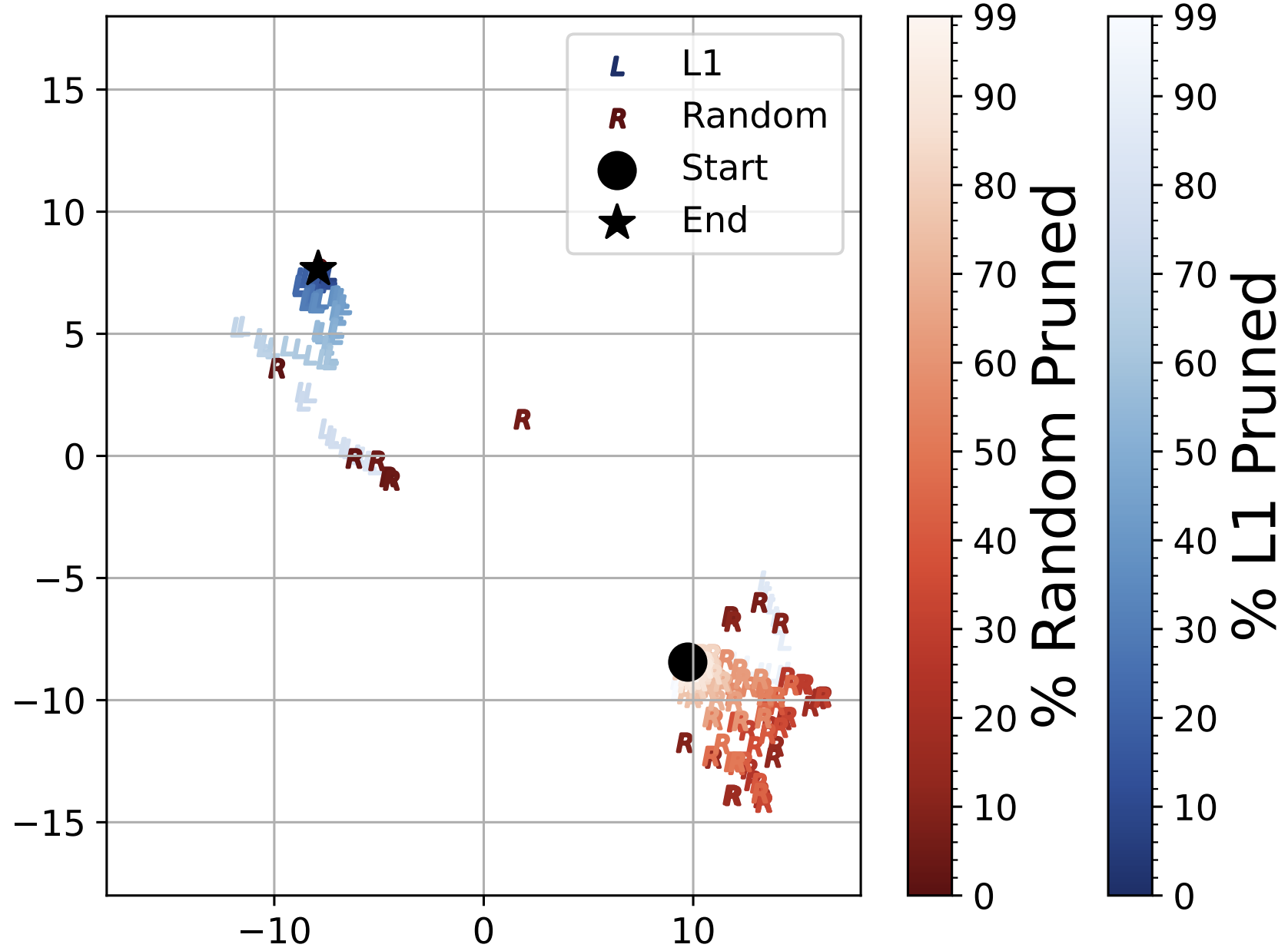 What makes a good prune? maximal unstructured pruning for maximal cosine similarityGabryel Mason-Williams and Fredrik DahlqvistIn The Twelfth International Conference on Learning Representations, 2024
What makes a good prune? maximal unstructured pruning for maximal cosine similarityGabryel Mason-Williams and Fredrik DahlqvistIn The Twelfth International Conference on Learning Representations, 2024Pruning is an effective method to reduce the size of deep neural network models, maintain accuracy, and, in some cases, improve the network’s overall performance. However, the mechanisms underpinning pruning remain unclear. Why can different methods prune by different percentages yet achieve similar performance? Why can we not prune at the start of training? Why are some models more amenable to being pruned than others? Given a model, what is the maximum amount it can be pruned before significantly affecting the performance? This paper explores and answers these questions from the global unstructured magnitude pruning perspective with one epoch of fine-tuning. We develop the idea that cosine similarity is an effective proxy measure for functional similarity between the parent and the pruned network. We prove that the L1 pruning method is optimal when pruning by cosine similarity. We show that the higher the kurtosis of a model’s parameter distribution, the more it can be pruned while maintaining performance. Finally, we present a simple method to determine the optimal amount by which a network can be L1-pruned based on its parameter distribution. The code demonstrating the method is available at https://github.com/gmw99/what makes a good prune
@inproceedings{mason2024makes, title = {What makes a good prune? maximal unstructured pruning for maximal cosine similarity}, author = {Mason-Williams, Gabryel and Dahlqvist, Fredrik}, booktitle = {The Twelfth International Conference on Learning Representations}, year = {2024} }
2022
-
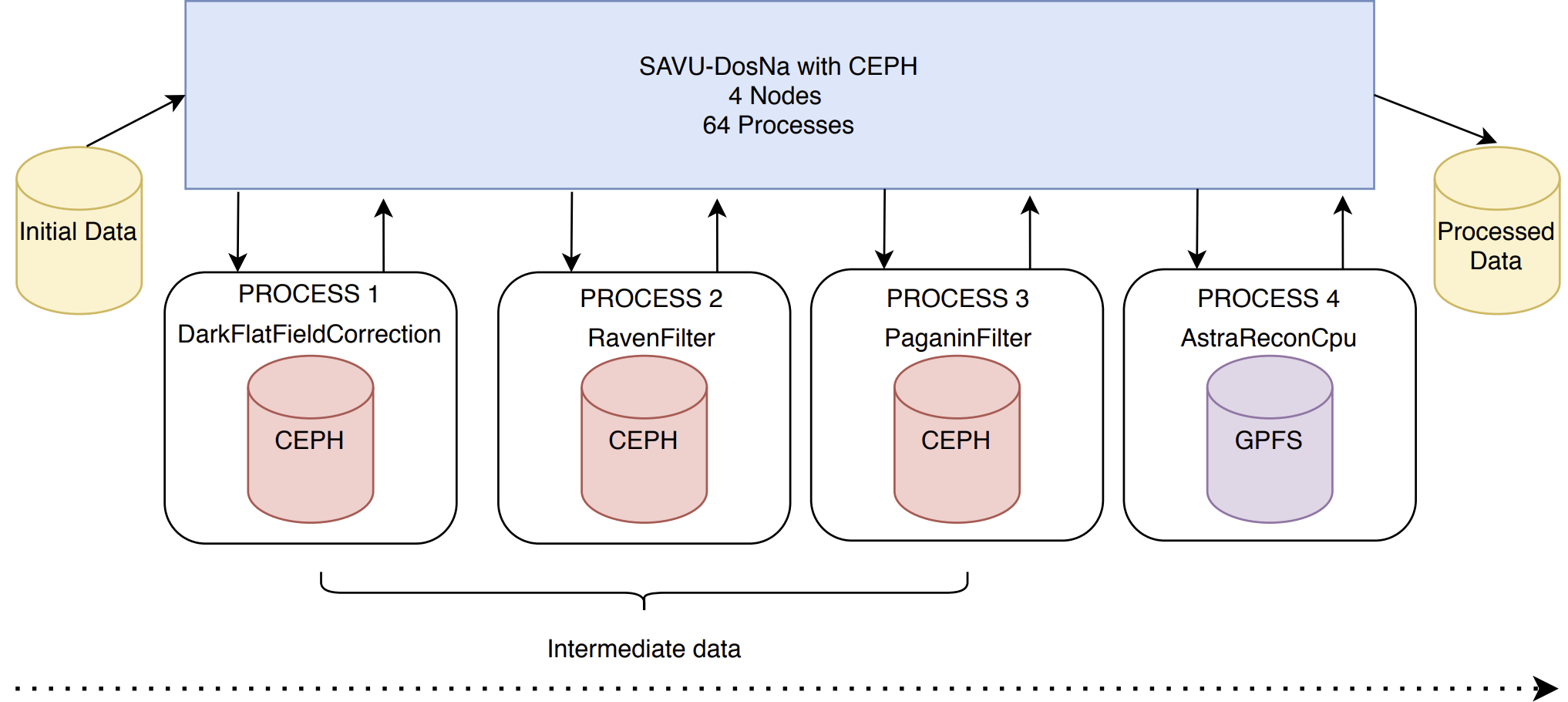 DisTRaC: Accelerating High Performance Compute Processing for Temporary Data StorageGabryel Mason-Williams, Dave Bond, and Mark Basham2022
DisTRaC: Accelerating High Performance Compute Processing for Temporary Data StorageGabryel Mason-Williams, Dave Bond, and Mark Basham2022High Performance Compute (HPC) clusters often produce intermediate files as part of code execution and message passing is not always possible to supply data to these cluster jobs. In these cases, I/O goes back to central distributed storage to allow cross node data sharing. These systems are often high performance and characterised by their high cost per TB and sensitivity to workload type such as being tuned to small or large file I/O. However, compute nodes often have large amounts of RAM, so when dealing with intermediate files where longevity or reliability of the system is not as important, local RAM disks can be used to obtain performance benefits. In this paper we show how this problem was tackled by creating a RAM block that could interact with the object storage system Ceph, as well as creating a deployment tool to deploy Ceph on HPC infrastructure effectively. This work resulted in a system that was more performant than the central high performance distributed storage system used at Diamond reducing I/O overhead and processing time for Savu, a tomography data processing application, by 81.04% and 8.32% respectively.
@misc{masonwilliams2022distracacceleratinghighperformance, title = {DisTRaC: Accelerating High Performance Compute Processing for Temporary Data Storage}, author = {Mason-Williams, Gabryel and Bond, Dave and Basham, Mark}, year = {2022}, eprint = {2212.03054}, archiveprefix = {arXiv}, primaryclass = {cs.DC}, }